文章目录
go源码分析之内存池
概述
go自带内存管理,主要是内存池和垃圾回收两部分。因为其对内存的管理在性能和空间利用率上的高效,go内存大多数情况不需要用户自己去管理内存,让程序员减少了很多在内存管理的心智成本。虽然如此,本文还是借着源码,分析下go的内存管理中内存池分配时如何实现的,希望对大家了解有所帮助。如有问题,欢迎探讨指正。
(源码基于go 1.10.3)
首先,内存分配模型基于tcmalloc,Tcmalloc是Google gperftools里的组件之一。全名是 thread cache malloc(线程缓存分配器),其内存管理分为线程内存和中央堆两部分。在并行程序下分配小对象(<=32k)的效率很高。
Tcmalloc核心思想是把内存分成多级来降低锁的粒度。每个线程都会有一个cache,用于无锁分配小对象,当内存不足分配小对象,就去central申请,在不足就去heap申请,heap最终是向操作系统申请。
这样的分配模型,维护一个用户态的内存池,不仅提高了内存在频繁分配、释放时的效率,而且有效地减少内存碎片。
下面我们依次看下go中内存如何划分,主要的一些内存结构,最后在结合源码看一下主要的内存分配流程。
内存划分
初始化时,go申请一段连续地址,并切分分为三块:spans bitmap areana
(详见runtime/malloc.go)
在64位系统中,他们对应关系是:
go中一个指针大小是8byte
arena区域就是heap,是供分配维护的内存池,对应区域大小是512G;
bitmap区域是标识arena中那些地址保存了对象,及对象中是否包含了指针,其中1个byte(8bit)对应arena中4个指针大小的内存(即:2bit对应1个指针大小),对应大小16G;
span是页管理单元,是内存分配的基本单位,其中一个指针对应arena中1个虚拟地址页大小(8kb),对应大小512M
也就是如下图的大小分配:

内存结构
如下图是整体的内存结构: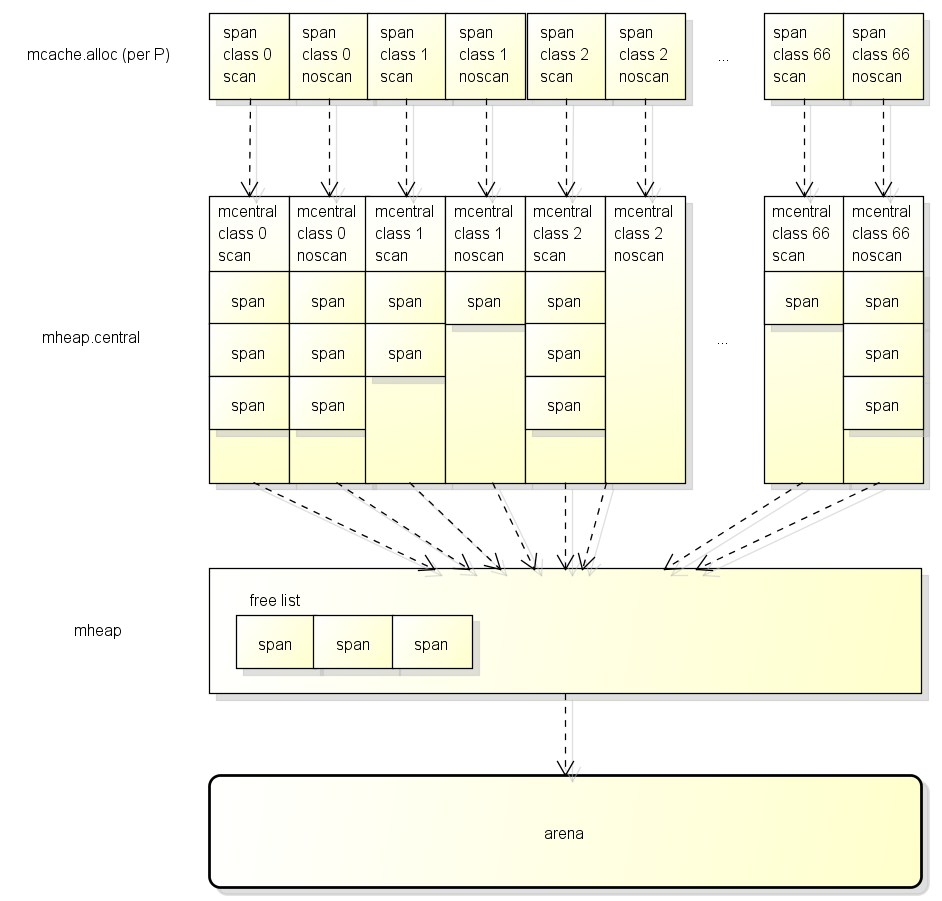
mspan
管理预分配页个数为sizeClass的连续地址内存,是基本的内存分配管理单位;
栈内存池(stack pool)就是使用mspan构成的链表来分配内存,具体见runtime/stack.go
(栈内存池是go协程启动是用来存储函数内变量,执行函数调用等;维护一个栈内存池,减少协程频繁启动退出的内存分配开销)
1 | type mspan struct { |
里边比较重要的几个点:
- freeindex
介于0~nelems的可用块的索引位置,是下一个可用块的位置;在freeindex之前的块都是已分配的,之后的可能已分配,可能未分配。 - allocBits
标记span中可用内存位置的bitmap,1标识可用 - allocCache
缓存了从freeindex开始的allocBits的bit位补集,这样分配前使用count tailing zero方式可快速定位地址
(关于count tailing zero的实现,感兴趣同学可以看下sys.Ctz64的实现) - spanclass
代表span的大小和是否需要gc扫描(既包含指针) - elemsize
小对象对应是sizeClass对应的块大小;大对象,对应是整数页的大小
mcache
go中每个P(GMP中的P,是系统线程M绑定的用来调度G的处理器,同一时间只有一个M可以拥有P)中用来缓存小对象的结构,无需加锁;
每个mcache中有大小为67个mspan数组,存储不同级别大小的mspan
可以理解为local cache
1 | type mcache struct { |
- alloc
是大小为67的指针数组,每个数组包含特定大小的块。 - tiny
指向mcache内存开始地址 - tinyoffset
记录tiny分配到什么位置(tiny对象分配完有剩余是,offset可用于下次分配计算)1
2
3每个sizeClass对应的大小(byte)
// sizeclasses.go
var class_to_size = [_NumSizeClasses]uint16{0, 8, 16, 32, 48, 64, 80, 96, 112, 128, 144, 160, 176, 192, 208, 224, 240, 256, 288, 320, 352, 384, 416, 448, 480, 512, 576, 640, 704, 768, 896, 1024, 1152, 1280, 1408, 1536, 1792, 2048, 2304, 2688, 3072, 3200, 3456, 4096, 4864, 5376, 6144, 6528, 6784, 6912, 8192, 9472, 9728, 10240, 10880, 12288, 13568, 14336, 16384, 18432, 19072, 20480, 21760, 24576, 27264, 28672, 32768}
mcentral
是指定大小的可用对象列表中枢
mcache不够用时,从mcentral分配nonempty中的span对象,每次分配时同时会处理可回收的span进行回收。
如果无可用span,则从heap中按需要的spanclass申请新的span
可理解为全局cache
1 | type mcentral struct { |
- nonempty
链接可用对象的链表 - empty
已被使用对象的列表 - nmalloc
mcentral累计分配出去的对象数
mheap
真实拥有虚拟地址的,管理小对象和大对象的内存分配,以及一些全局变量
1 | type mheap struct { |
- free
记录小对象分配 - freelarge
记录大对象分配(>32k),mTreap是基于BestFit分配算法实现的树堆。树堆中每个节点是一整个span,树堆按页大小排序,页大小相同时按内存起始地址排序。
基于BestFit算法返回span时,如果span大小相同,先返回在地址最小的span。
详见mgclarge.go - allspans
每个分配出的span - spans
映射mspan和arena的page对应关系的查询表(如前所说span一个指针对应bitmap一页) - central
用于管理小对象的空闲链表,按spanClass索引 - arena_start,arena_used
记录areana分配
注意到其中span,cache,treap都是用fixalloc来分配,这是一个free-list的块分配器,用来分配指定大小的块。
1 | type fixalloc struct { |
分配时,如果list为空,则申请一整块内存(chunk),每次按需分配;释放时再放回list中。
因为size是固定,所以没有内存碎片产生。
内存分配流程
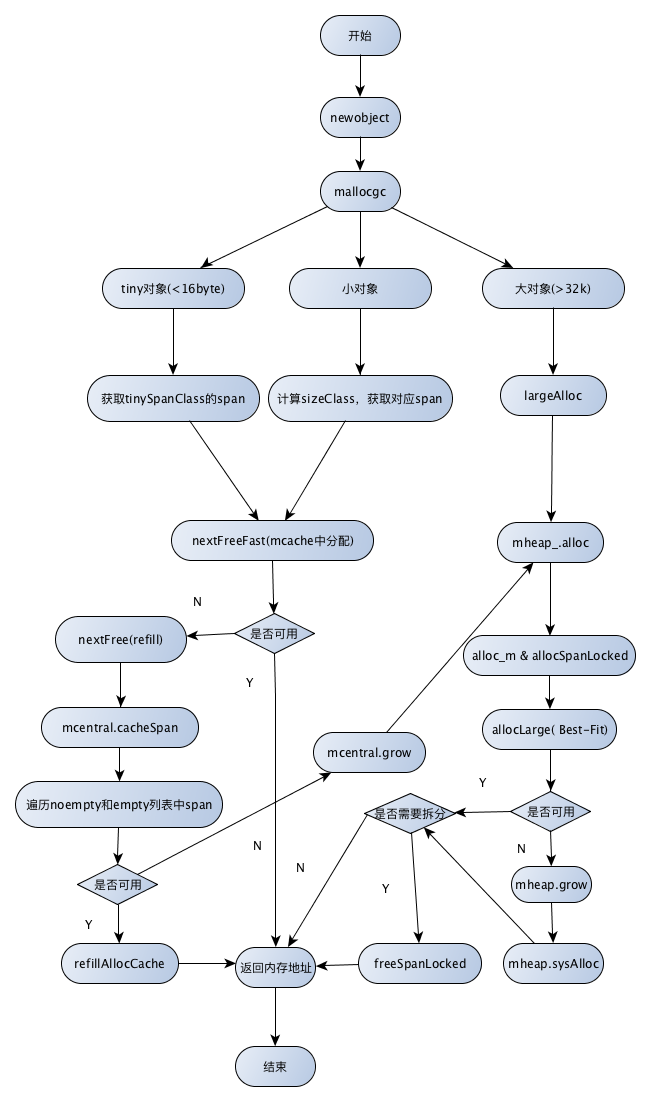
对象分配
- size > 32k,是大对象,直接从mheap中分配
- size < 16B,使用mcache的tiny allocator分配,将小对象合并存储
分配前会按大小先地址对齐
1.对于大于等于8B的对象,其内存地址按照8B对齐;
2.对于小于8B大于等于4B的对象,其内存地址按照4B对齐;
3.对于小于4B大于1B的对象,其内存地址按照2B对齐;
4.对于1B对象,无对齐要求。
这样对齐会有部分内存浪费,但却能提升内存访问的效率。
- size 在16B ~ 32k 间,计算需要使用的sizeClass,然后使用mcache中对应的sizeClass的块分配
- 如果mcache对应的sizeClass已无可用块,则向mcentral申请
- 如果mcentral也没有可用的块,则向mheap申请,使用BestFit找到最合适的mspan。如果超过申请大小则按需切分,返回用户需要的页面数,剩余的页面构成一个新的mspan,放回mheap的空闲链表
- 如果mheap也无可用span,则向操作系统申请一组新的页(至少1MB)
对象释放
- 查找对象所属的类型大小,放入对应的mcache空闲链表
- 如果mcache空闲链表太长或者内存太大,则返回给mcentral的空闲链表
- 如果在某个范围的所有对象都归还给mcentral了,则将他归还给mheap
具体见runtime/mgcsweep.go mspan.sweep,这里不展开
下面结合源码看下分配流程
1 | func newobject(typ *_type) unsafe.Pointer { |
总结
Go内存管理内存池的总体思路是,针对不同大小的对象,使用不同的内存结构分配内存。对操作系统申请的一整块连续地址,进行切分,多级缓存。对内存分配都按规定大小分配,减少内存碎片,也利于内存释放后,回收管理。
针对小对象(< 16byte),使用当前调度器(p)的mcache中的tiny allocator来分配,这样多个小对象可以放一起管理,避免内存浪费。
针对稍大对象(16byte ~ 32K),是用指定sizeClass取对应的块来分配。
针对大对象(>32K),直接从heap中分配
其中mcache不足向mcentral中申请、mcentral不足向mheap申请,这些请求都是一次申请平摊了加锁(mcentral或mheap)的开销;
mheap不足向操作系统申请一组页,则是平摊了操作系统分配的开销;
同时设计mcentral - 全局的cache 和 mcache - 每个调度器cache,便于中小对象快速分配和回收,提高内存分配的效率,避免每次和操作系统申请的io开销,是用空间换时间的方式。
参考
http://www.cnblogs.com/zkweb/p/7880099.html
https://studygolang.com/articles/11030
http://www.cnblogs.com/zkweb/p/7880099.html
如有疑问,请文末留言交流或邮件:newbvirgil@gmail.com本文链接 : https://newbmiao.github.io/2018/08/20/go-source-analysis-of-memory-alloc.html
