文章目录
Dig101: dig more, simplified more and know more
string这么简单,我想你也一直是这样想的,没关系,我也没打算把它搞复杂。
别着急,我们先从string的拼接操作 + 开始
0x01 string对 “+” 拼接的优化
如下代码, s2, s3, s4 具体执行时有啥不同
1 | s1 := "x" |
乍一看都是字符串拼接感觉没啥不同,但是当我们用go tool compile -m来打印编译优化时发现
字面量拼接会在编译时就合并到一起"y" + "x" + "z" => "xyz"
1 | $ go tool compile -m plus.go |
再使用-S打印汇编调用concat相关
1 | $ go tool compile -S plus.go|grep concat |
发现这三个拼接调用了不同的concatstring方法
其实当string相加是:
- 编译器先优化掉字面量拼接后
- 再将剩余待拼接
string作为一个切片参数传入concatstring相关函数- 当切片长度为 2-5 之间则调用数组参数的
concatstring2-concatstring5 - 否则调用切片参数的
concatstrings
- 当切片长度为 2-5 之间则调用数组参数的
- 如果所有待拼接
string总长度小于32, 则会初始化一个栈上的tmpBuf,来避免堆上内存分配。
具体代码调用点如下,感兴趣可以自行查看下
1 | // cmd/compile/internal/gc/walk.go 中 addstr |
0x02 string也是一种切片
如果你查看过concatstrings的内部调用,你会发现有切片的操作
1 | func concatstrings(buf *tmpBuf, a []string) string |
重点就是*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
所以string底层不过是cap和len一样的[]byte罢了
0x03 string不能修改
1 | s:="abc" |
那一般怎么改局部字符呢, 有两类利用[]byte和[]rune
1 | s := "abc好" |
0x04 string和[]byte,[]rune的相互转化
那么对于上边的转化,我们可以依次分析一下,会有一些有趣的地方
rune => string
每个rune底层是int32,是用来utf8字符表示的编码点(Unicode code point),4个byte(uint8)大小
转化前内部先开辟[]byte, 再调用 func encoderune(p []byte, r rune)
判断r底层的[]byte大小, 依次实现拷贝写入。
这里如果你仔细查看encoderune函数,
诸如 _ = p[1],_ = p[2] ...
其实是一种边界检查的优化:消除边界检查。
感兴趣的同学可以自行查看
byte => string
直接基于[]byte的首地址和长度构造string结构体,并拷贝内容到数据指向
string => rune
直接开辟[]rune, 遍历string为[]rune赋值
因为string遍历等价于对[]rune(string)的遍历
另外string不可修改,所以转换中不需要检测数据竞争(race detect)
string => byte
直接开辟[]byte, 利用copy([]byte, string)拷贝
0x05 零拷贝实现[]byte转string
上边的转化方式都有拷贝,有一种不需要拷贝就可以将[]byte转为string
出现在如下函数
1 | // 有些编译器会对以下操作中的转string使用优化 |
原理就是利用string底层是[]byte,所以直接做指针转换。
但是有注意点,转换后不能修改,否则string不可被修改的原则就被破坏了。属于特定使用场景了。
string拼接类库strings.Builder的String方法就利用这一点零拷贝优化转化速度
0x06 string的拼接效率
针对长(long: 256b)、短string(short: 16b)在少量和大量拼接的benchmark,代码见concat_benchmark
对于sprint和sprintf和strings.Join压测代码都是提前构建好全部待拼接string列表
其他三个是遍历拼接
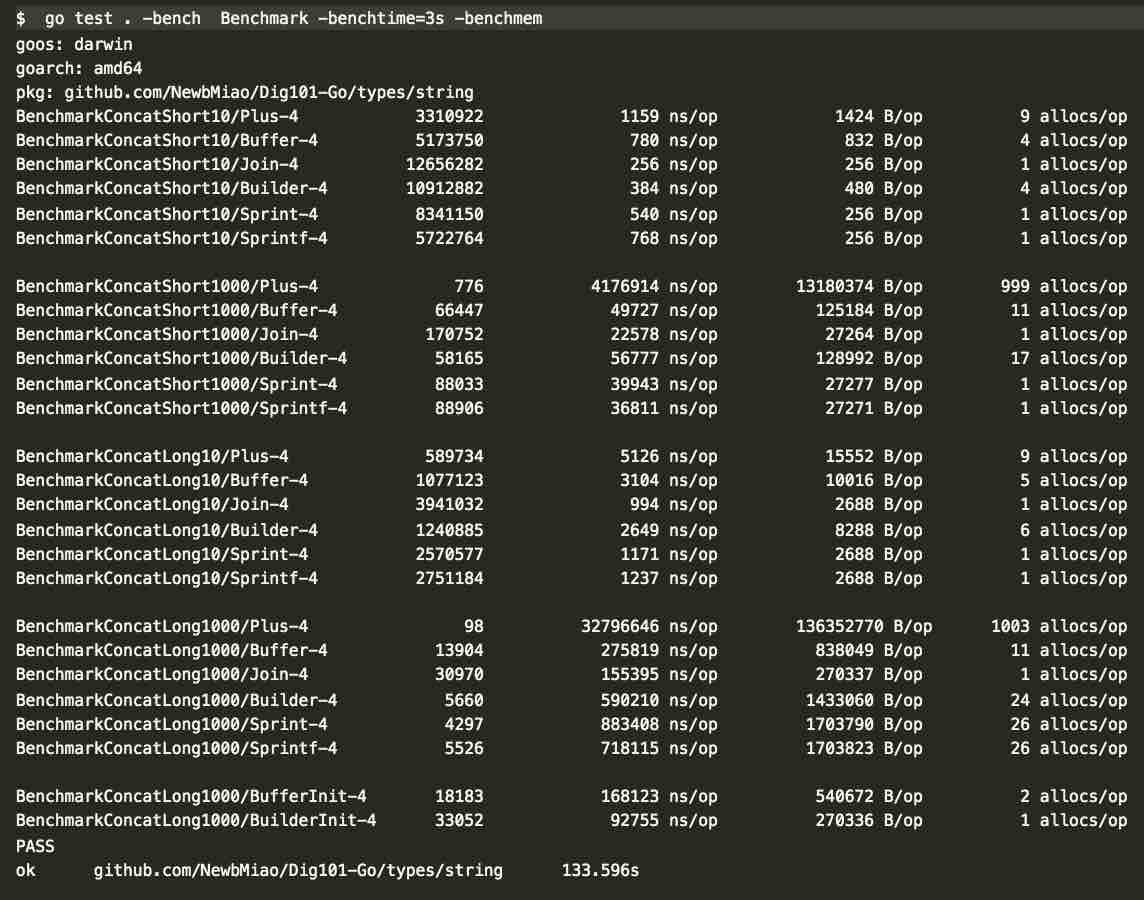
压测结果分析如下:
提前构造好参数情况下
sprint和sprintf差别不大strings.Join效率最佳(其底层使用strings.Builder这个我们后边对比时再讲)
遍历拼接情况下
+性能差距会越来越大- 少量拼接次数下:
strings.Builder比bytes.Buffer快, 大量了就不行了
可是官方宣称strings.Builder在结果为string情况下效率更好啊。
仔细看我们发现strings.Builder对应的每次操作alloc数比buffer的多很多,可能是内存分配过多影响了效率。查看压测代码,都是遍历前bf.Reset()重置。
再看源码
1 | // Reset resets the buffer to be empty, |
原来Buffer只是将大小设置为0,没清空内容,而Builder直接清空了内容
也对,Builder利用了零拷贝优化转化string的效率,是不允许修改的。
这也是为啥其内部写操作之前会调用b.copyCheck()去检测是否存在拷贝。
除此之外,其实Buffer和Builder还有优化的空间:就是减少内存分配次数
他们底层都使用了[]byte,且都有Grow(size int)方法,所以可以一次分配好大小,
避免多次内存不够去reslice扩容, 详见代码: concatIterWithGrowInit
如此优化后,benchmark的数据能和官方说的对上了,Builder变快了,而且他们每次操作的alloc次数都变成了1.

好了,就到这里,希望我没把它搞复杂。
本文代码见 NewbMiao/Dig101-Go
如有疑问,请文末留言交流或邮件:newbvirgil@gmail.com本文链接 : https://newbmiao.github.io/2020/01/18/dig101-golang-string.html
